你的个人
研究助理
188BET靠谱吗Zotero是一个免费的,易于使用的工具来帮助你收集,组织,注释,引用和分享研究。
适用于Mac、Windows、Linux和iOS
只需要创建一个快速的参考书目?试一试188BET靠谱吗ZoteroBib.
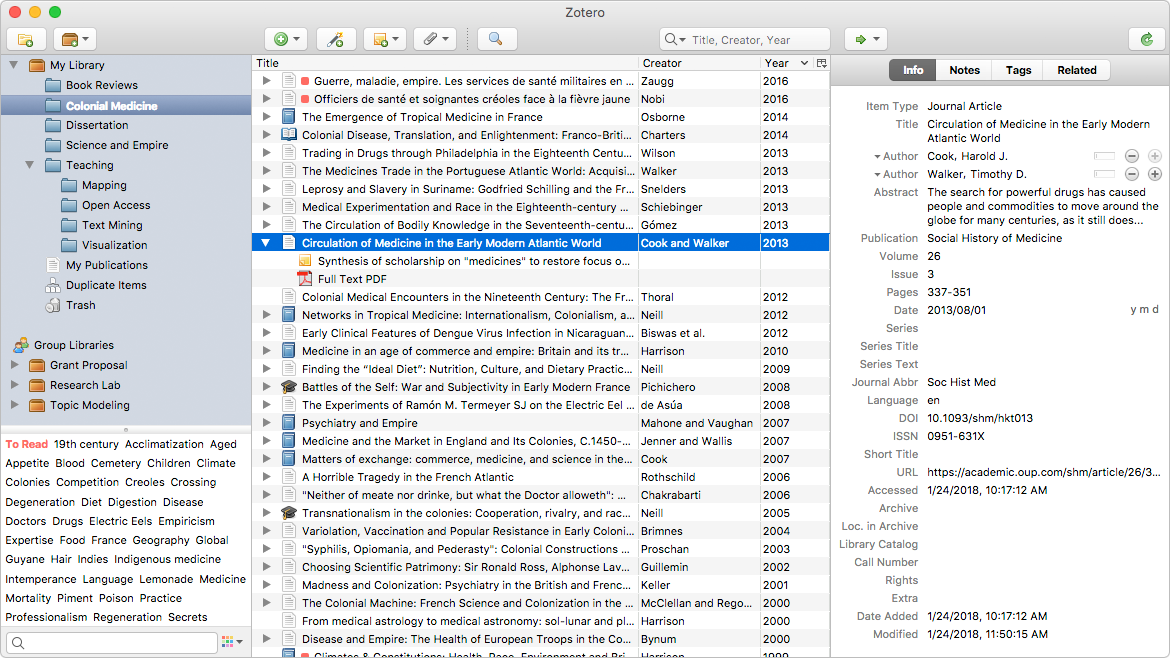
Zoter188BET靠谱吗o见面。

点击收集。
188BET靠谱吗当你浏览网页时,Zotero会自动感知研究。需要一篇文章从JSTOR或预印从arXiv.org?是《纽约时报》的新闻报道还是图书馆的书?188BET靠谱吗Zotero让你无处不在。

组织你的方式。
188BET靠谱吗Zotero帮助你组织你的研究任何你想要的方式。188金宝搏BET真人您可以将项目分类到集合中,并使用关键字标记它们。或者创建保存的搜索,在工作时自动填充相关材料。

引用在风格。
188BET靠谱吗Zotero立即为任何文本编辑器创建引用和书目,并直接在Word, LibreOffice和谷歌文档中。支持超过10,000种引用风格,您可以格式化您的工作,以匹配任何风格指南或出版物。

保持同步。
188BET靠谱吗Zotero可以选择性地跨设备同步您的数据,保持您的文件,笔记和书目记录无缝更新。如果你决定同步,你也可以随时从任何网页浏览器访问你的研究。

自由合作。
188BET靠谱吗Zotero可以让你和同事共同写一篇论文,向学生分发课程材料,或者建立一个合作书目。你可以免费和很多人共享一个Zot188BET靠谱吗ero图书馆。

高枕无忧。
188BET靠谱吗Zotero是开源它是由一个独立的非营利组织开发的,对你的私人信息没有经济利益。188金宝慱亚洲体育官网首页20使用Zot188BET靠谱吗ero,你可以一直控制自己的数据。
还不确定用哪个程序进行研究?看到为什么我们认为你应该选择Zotero188BET靠谱吗.